Partitioned search
1. Algorithm description
It is often more efficient to partition large data sets (usually above 5000 planning entities) into smaller pieces and solve them separately. Partition Search is multithreaded, so it provides a performance boost on multi-core machines due to higher CPU utilization. Additionally, even when only using one CPU, it finds an initial solution faster, because the search space sum of a partitioned Construction Heuristic is far less than its non-partitioned variant.
However, partitioning does lead to suboptimal results, even if the pieces are solved optimally, as shown below:
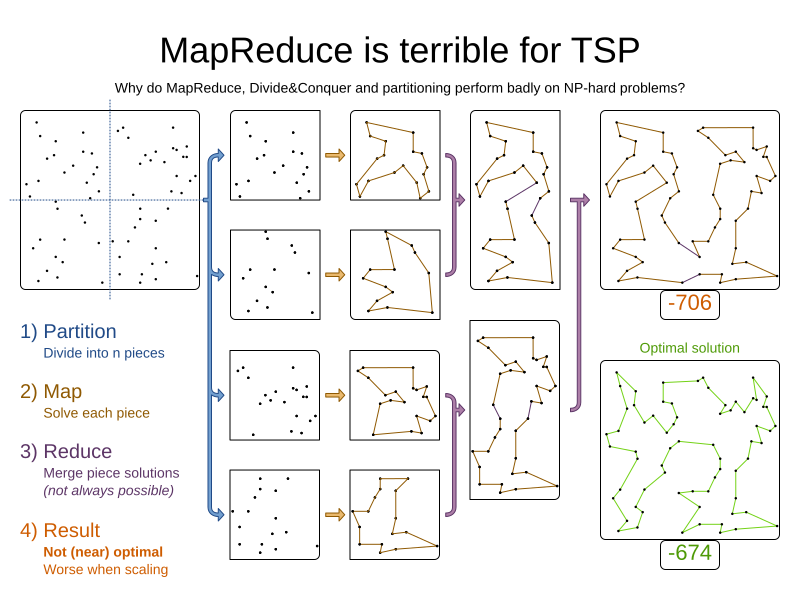
It effectively trades a short term gain in solution quality for long term loss. One way to compensate for this loss, is to run a non-partitioned Local Search after the Partitioned Search phase.
|
Not all use cases can be partitioned. Partitioning only works for use cases where the planning entities and value ranges can be split into n partitions, without any of the constraints crossing boundaries between partitions. |
2. Configuration
Simplest configuration:
<partitionedSearch>
<solutionPartitionerClass>ai.timefold.solver.examples.cloudbalancing.optional.partitioner.CloudBalancePartitioner</solutionPartitionerClass>
</partitionedSearch>Also add a @PlanningId annotations on every planning entity class and planning value class. There are several ways to partition a solution.
Advanced configuration:
<partitionedSearch>
...
<solutionPartitionerClass>ai.timefold.solver.examples.cloudbalancing.optional.partitioner.CloudBalancePartitioner</solutionPartitionerClass>
<runnablePartThreadLimit>4</runnablePartThreadLimit>
<constructionHeuristic>...</constructionHeuristic>
<localSearch>...</localSearch>
</partitionedSearch>The runnablePartThreadLimit allows limiting CPU usage to avoid hanging your machine, see below.
To run in an environment that doesn’t like arbitrary thread creation, plug in a custom thread factory.
|
A logging level of |
Just like a <solver> element, the <partitionedSearch> element can contain one or more phases.
Each of those phases will be run on each partition.
A common configuration is to first run a Partitioned Search phase (which includes a Construction Heuristic and a Local Search) followed by a non-partitioned Local Search phase:
<partitionedSearch>
<solutionPartitionerClass>...CloudBalancePartitioner</solutionPartitionerClass>
<constructionHeuristic/>
<localSearch>
<termination>
<secondsSpentLimit>60</secondsSpentLimit>
</termination>
</localSearch>
</partitionedSearch>
<localSearch/>3. Partitioning a solution
3.1. Custom SolutionPartitioner
To use a custom SolutionPartitioner, configure one on the Partitioned Search phase:
<partitionedSearch>
<solutionPartitionerClass>ai.timefold.solver.examples.cloudbalancing.optional.partitioner.CloudBalancePartitioner</solutionPartitionerClass>
</partitionedSearch>Implement the SolutionPartitioner interface:
public interface SolutionPartitioner<Solution_> {
List<Solution_> splitWorkingSolution(ScoreDirector<Solution_> scoreDirector, Integer runnablePartThreadLimit);
}The size() of the returned List is the partCount (the number of partitions).
This can be decided dynamically, for example, based on the size of the non-partitioned solution.
The partCount is unrelated to the runnablePartThreadLimit.
For example:
public class CloudBalancePartitioner implements SolutionPartitioner<CloudBalance> {
private int partCount = 4;
private int minimumProcessListSize = 75;
@Override
public List<CloudBalance> splitWorkingSolution(ScoreDirector<CloudBalance> scoreDirector, Integer runnablePartThreadLimit) {
CloudBalance originalSolution = scoreDirector.getWorkingSolution();
List<CloudComputer> originalComputerList = originalSolution.getComputerList();
List<CloudProcess> originalProcessList = originalSolution.getProcessList();
int partCount = this.partCount;
if (originalProcessList.size() / partCount < minimumProcessListSize) {
partCount = originalProcessList.size() / minimumProcessListSize;
}
List<CloudBalance> partList = new ArrayList<>(partCount);
for (int i = 0; i < partCount; i++) {
CloudBalance partSolution = new CloudBalance(originalSolution.getId(),
new ArrayList<>(originalComputerList.size() / partCount + 1),
new ArrayList<>(originalProcessList.size() / partCount + 1));
partList.add(partSolution);
}
int partIndex = 0;
Map<Long, Pair<Integer, CloudComputer>> idToPartIndexAndComputerMap = new HashMap<>(originalComputerList.size());
for (CloudComputer originalComputer : originalComputerList) {
CloudBalance part = partList.get(partIndex);
CloudComputer computer = new CloudComputer(
originalComputer.getId(),
originalComputer.getCpuPower(), originalComputer.getMemory(),
originalComputer.getNetworkBandwidth(), originalComputer.getCost());
part.getComputerList().add(computer);
idToPartIndexAndComputerMap.put(computer.getId(), Pair.of(partIndex, computer));
partIndex = (partIndex + 1) % partList.size();
}
partIndex = 0;
for (CloudProcess originalProcess : originalProcessList) {
CloudBalance part = partList.get(partIndex);
CloudProcess process = new CloudProcess(
originalProcess.getId(),
originalProcess.getRequiredCpuPower(), originalProcess.getRequiredMemory(),
originalProcess.getRequiredNetworkBandwidth());
part.getProcessList().add(process);
if (originalProcess.getComputer() != null) {
Pair<Integer, CloudComputer> partIndexAndComputer = idToPartIndexAndComputerMap.get(
originalProcess.getComputer().getId());
if (partIndexAndComputer == null) {
throw new IllegalStateException("The initialized process (" + originalProcess
+ ") has a computer (" + originalProcess.getComputer()
+ ") which doesn't exist in the originalSolution (" + originalSolution + ").");
}
if (partIndex != partIndexAndComputer.getLeft().intValue()) {
throw new IllegalStateException("The initialized process (" + originalProcess
+ ") with partIndex (" + partIndex
+ ") has a computer (" + originalProcess.getComputer()
+ ") which belongs to another partIndex (" + partIndexAndComputer.getLeft() + ").");
}
process.setComputer(partIndexAndComputer.getRight());
}
partIndex = (partIndex + 1) % partList.size();
}
return partList;
}
}To configure values of a SolutionPartitioner dynamically in the solver configuration
(so the Benchmarker can tweak those parameters),
add the solutionPartitionerCustomProperties element and use custom properties:
<partitionedSearch>
<solutionPartitionerClass>...CloudBalancePartitioner</solutionPartitionerClass>
<solutionPartitionerCustomProperties>
<property name="myPartCount" value="8"/>
<property name="myMinimumProcessListSize" value="100"/>
</solutionPartitionerCustomProperties>
</partitionedSearch>4. Runnable part thread limit
When running a multithreaded solver, such as Partitioned Search, CPU power can quickly become a scarce resource, which can cause other processes or threads to hang or freeze. However, Timefold has a system to prevent CPU starving of other processes (such as an SSH connection in production or your IDE in development) or other threads (such as the servlet threads that handle REST requests).
As explained in sizing hardware and software,
each solver (including each child solver) does no IO during solve() and therefore saturates one CPU core completely.
In Partitioned Search, every partition always has its own thread, called a part thread.
It is impossible for two partitions to share a thread,
because of asynchronous termination: the second thread would never run.
Every part thread will try to consume one CPU core entirely, so if there are more partitions than CPU cores,
this will probably hang the system.
Thread.setPriority() is often too weak to solve this hogging problem, so another approach is used.
The runnablePartThreadLimit parameter specifies how many part threads are runnable at the same time.
The other part threads will temporarily block and therefore will not consume any CPU power.
This parameter basically specifies how many CPU cores are donated to Timefold.
All part threads share the CPU cores in a round-robin manner
to consume (more or less) the same number of CPU cycles:
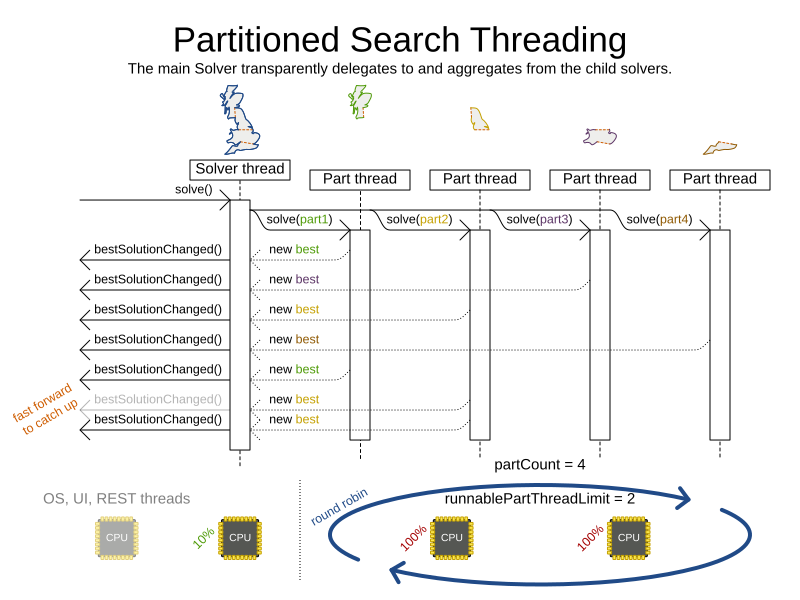
The following runnablePartThreadLimit options are supported:
-
UNLIMITED: Allow Timefold to occupy all CPU cores, do not avoid hogging. Useful if a no hogging CPU policy is configured on the OS level. -
AUTO(default): Let Timefold decide how many CPU cores to occupy. This formula is based on experience. It does not hog all CPU cores on a multi-core machine. -
Static number: The number of CPU cores to consume. For example:
<runnablePartThreadLimit>2</runnablePartThreadLimit>
|
If the |